




Subqueries remain one of the most powerful features in SQL. They can be used to filter data, generate values, and construct temporary data sets.
What is a subquery?
A subquery is a query contained within another statement (containing statement). It is usually enclosed within parentheses, and always executed before the containing statement. Just like any other query, a subquery returns a result set that may consist of:
- A single row with a single column
- Multiple rows with a single column
- Multiple rows with multiple columns
The type of result set returned by a subquery determines how it can be used and what operators can be used by the containing statement to interact with the data the subquery returns. Once the containing statement executes, data returned by any subquery is discarded, making a subquery act as a temporary table with a statement scope (server frees up any memory allocated to the subquery results once an SQL statement finishes executing).
I’ll be making reference to the popular Sakila database that is available online and experimenting with a few tables from the database using MySQL. Here’s an example of a subquery to get started:
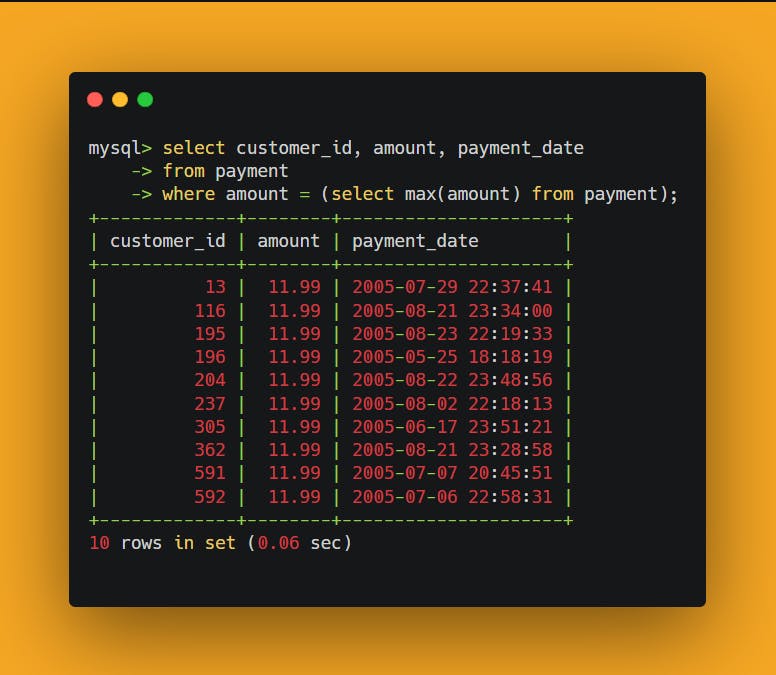
In this example, the subquery returns the maximum value in the amount column in the payment table, and the containing statement then returns data about that payment or payments.
To better comprehend this, let us run the subquery by itself to see what it returns:
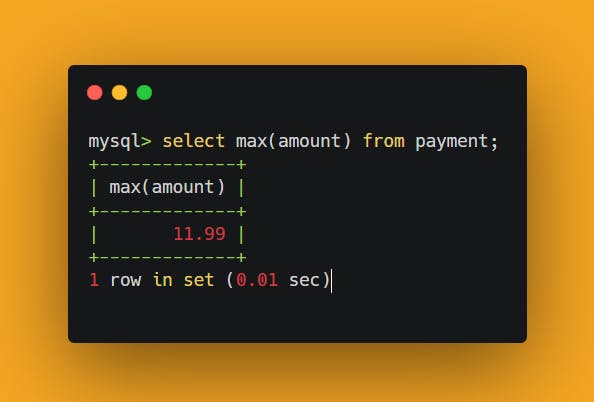
The subquery returns a single row with a single column, which allows it to be used as an expression in an equality condition (if the subquery returned two or more rows, it could be compared to something, but could not be equal to anything).
Let’s take the value returned by the subquery and substitute it in the righthand expression of the filter condition in the containing query and see what happens:
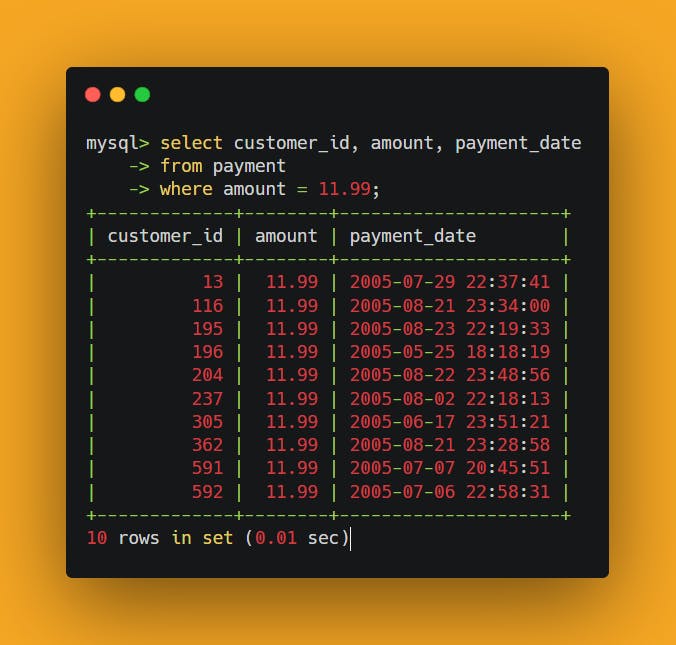
The subquery is important in this case because it allows you to retrieve information about the payment(s) with the highest amount in a single query, rather than retrieving the maximum amount in one query, then using a second query to retrieve the desired data from the payment table.
Subquery Types
Some subqueries are completely self-contained (noncorrelated subqueries) – meaning they could be run independently, while others reference columns from the containing statement (correlated subqueries).
Noncorrelated subqueries
The earlier first example we used is an example of a noncorrelated subquery; it can be executed alone and does not reference anything in the containing statement. Most subqueries are of this type unless you’re writing update and delete statements, which often make use of correlated subqueries.
Correlated subqueries
A correlated subquery is dependent on the containing statement, from which, it references one or more columns. Unlike a noncorrelated subquery, a correlated subquery is not executed once prior to execution of its containing statement; instead, it’s executed once for every candidate row (rows that might be included in the final results).
For example, the following query uses a subquery to count the number of payments for each customer, and the containing statement then retrieves those customers who’ve made over 15 payments.
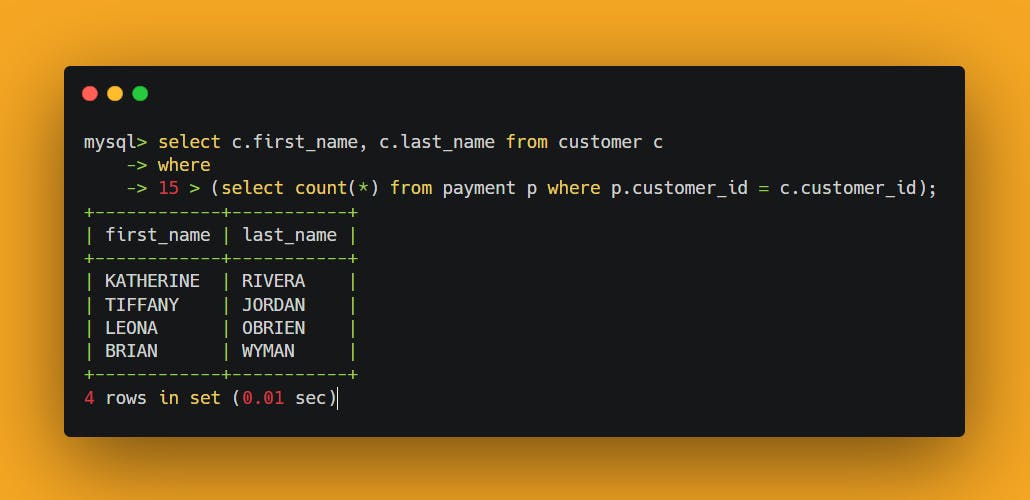
The reference to c.customer_id at the very end of the subquery is what makes it correlated, meaning, the containing query must supply values for c.customer_id for the subquery to execute. Attempting to run the subquery on its own would therefore result in an error.
Wrap Up
This article only provides a brief introduction to SQL subqueries. For more information, there are a lot of articles online that can help you dig deeper.
Don't forget to share and give the article a thumbs up if you find it helpful!